



LORA权重合并
环境安装
依次执行以下命令:
conda create -n 4b-merge python=3.11 -y
conda activate 4b-merge
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
pip install accelerate==1.13.0
pip install optimum==2.1.0
pip install transformers==4.57.1
pip install peft==0.18.1合并脚本
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model = "/data/tele/ai/.models/MiniCPM3-4B_20251226"
lora_model = "/data/tele/ai/.models/lora_20260213"
output_model = "/data/tele/ai/.models/MiniCPM3-4B_20251226-lora"
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
base_model,
dtype="auto",
device_map="auto",
trust_remote_code=True
)
model = PeftModel.from_pretrained(model, lora_model)
model = model.merge_and_unload()
model.save_pretrained(output_model)
tokenizer.save_pretrained(output_model)执行合并
执行脚本
python3 minicpm3-merged.py打印如下,需要耐心等待

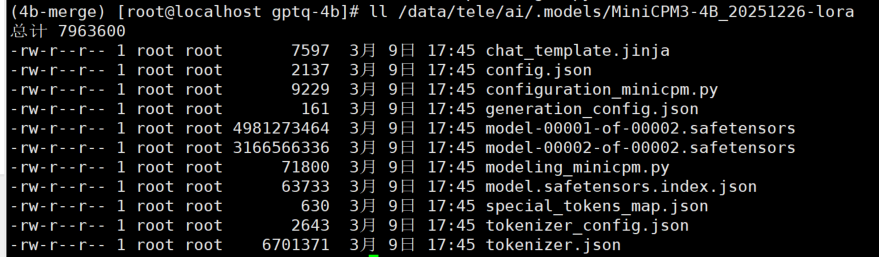
合并成
MiniCPM3-4B量化(gptq)
环境安装
conda create -n 4b-gptq python=3.11 -y
conda activate 4b-gptq
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
pip install -v gptqmodel --no-build-isolation
pip install transformers==4.57.1
量化脚本
import torch
from transformers import AutoTokenizer
from datasets import load_dataset
from gptqmodel import GPTQModel, QuantizeConfig
# ===== 模型路径 =====
model_path = "/data/tele/ai/.models/MiniCPM3-4B_20251226-lora-merged"
quantized_model_path = "/data/tele/ai/.models/MiniCPM3-4B-GPTQ"
# ===== tokenizer =====
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# ===== 量化配置 =====
quantize_config = QuantizeConfig(
bits=4, # 4bit量化
group_size=128, # GPTQ推荐128
desc_act=False, # 推理更快
sym=True
)
# ===== 加载模型 =====
model = GPTQModel.from_pretrained(
model_path,
quantize_config,
trust_remote_code=True,
device="cuda:0"
)
# ===== 准备校准数据 =====
dataset = load_dataset(
"wikitext",
"wikitext-2-raw-v1",
split="train"
)
calibration_texts = dataset["text"][:512]
calibration_examples = []
for text in calibration_texts:
if len(text.strip()) == 0:
continue
tokens = tokenizer(
text,
truncation=True,
max_length=2048,
return_tensors="pt"
)
calibration_examples.append(tokens)
# ===== 执行量化 =====
model.quantize(calibration_examples)
# ===== 保存量化模型 =====
model.save_quantized(quantized_model_path)
tokenizer.save_pretrained(quantized_model_path)
print("GPTQ quantization finished!")
print("Model saved to:", quantized_model_path)执行量化
执行以下命令开始量化:
## 下载校准数据的时候会快一些
export HF_ENDPOINT=https://hf-mirror.com
python3 minicpm3-gptq.py
量化成功:
结果信息:
INFO tp-pre-pad summary:
[]
INFO | Submodule finalize | 992 | 0.174 | 0.290 | 287.958 | 35.1% | model.layers.61.mlp.gate_proj |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Process quant | 992 | 0.725 | 0.172 | 170.954 | 20.8% | model.layers.61.mlp.down_proj |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Finalize create | 496 | 0.060 | 0.270 | 134.118 | 16.3% | model.layers.61.mlp.gate_proj |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Pre-quant forward | 310 | 0.341 | 0.279 | 86.366 | 10.5% | model.layers.61:subset5/5 |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Finalize pack | 496 | 0.098 | 0.164 | 81.543 | 9.9% | model.layers.61.mlp.gate_proj [module.pack_block] |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Forward hook | 155248 | 0.000 | 0.000 | 22.477 | 2.7% | model.layers.61.mlp.down_proj |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Post-quant replay | 61 | 0.303 | 0.284 | 17.315 | 2.1% | model.layers.60:subset5/5 |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Finalize offload | 496 | 0.005 | 0.024 | 11.904 | 1.4% | model.layers.61.mlp.gate_proj |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Turtle reload | 13 | 0.438 | 0.371 | 4.822 | 0.6% | auto:MiniCPMDecoderLayer |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Capture inputs | 1 | 3.646 | 3.646 | 3.646 | 0.4% | cache_inputs:MiniCPMDecoderLayer |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO | Process finalize | 2 | 0.000 | 0.000 | 0.000 | 0.0% | tp-pre-pad |
INFO +--------------------+--------+--------+-------+---------+--------+-----------------------------------------------------------------+
INFO Saved Quantize Config:
{
"bits": 4,
"group_size": 128,
"desc_act": false,
"lm_head": false,
"quant_method": "gptq",
"checkpoint_format": "gptq",
"pack_dtype": "int32",
"meta": {
"quantizer": [
"gptqmodel:5.7.0"
],
"uri": "https://github.com/modelcloud/gptqmodel",
"damp_percent": 0.05,
"damp_auto_increment": 0.01,
"static_groups": false,
"true_sequential": true,
"mse": 0.0,
"gptaq": null,
"act_group_aware": true,
"failsafe": {
"strategy": "rtn",
"threshold": "0.5%",
"smooth": {
"type": "mad",
"group_size_threshold": 128,
"k": 2.75
}
},
"offload_to_disk": true,
"offload_to_disk_path": "./gptqmodel_offload/hqdpgrum-rkaakpxx/",
"pack_impl": "cpu",
"mock_quantization": false,
"gc_mode": "interval",
"wait_for_submodule_finalizers": false,
"auto_forward_data_parallel": true,
"hessian": {
"chunk_size": null,
"chunk_bytes": null,
"staging_dtype": "float32"
},
"vram_strategy": "exclusive"
},
"sym": true,
"format": "gptq"
}
Files in directory:
quant_log.csv
modeling_minicpm.py
configuration_minicpm.py
config.json
generation_config.json
quantize_config.json
Content of saved `generation_config.json`:
{
"bos_token_id": 1,
"do_sample": true,
"eos_token_id": [
2,
73440
],
"temperature": 0.8,
"top_p": 0.8,
"transformers_version": "4.57.1"
}
Content of saved `config.json`:
{
"architectures": [
"MiniCPM3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"auto_map": {
"AutoConfig": "configuration_minicpm.MiniCPM3Config",
"AutoModel": "modeling_minicpm.MiniCPM3Model",
"AutoModelForCausalLM": "modeling_minicpm.MiniCPM3ForCausalLM",
"AutoModelForSeq2SeqLM": "modeling_minicpm.MiniCPM3ForCausalLM",
"AutoModelForSequenceClassification": "modeling_minicpm.MiniCPM3ForSequenceClassification"
},
"bos_token_id": 1,
"dim_model_base": 256,
"dtype": "bfloat16",
"eos_token_id": [
2,
73440
],
"head_dim": 96,
"hidden_act": "silu",
"hidden_size": 2560,
"initializer_range": 0.1,
"intermediate_size": 6400,
"kv_lora_rank": 256,
"max_position_embeddings": 32768,
"model_type": "minicpm3",
"num_attention_heads": 40,
"num_hidden_layers": 62,
"num_key_value_heads": 40,
"pretraining_tp": 1,
"q_lora_rank": 768,
"qk_nope_head_dim": 64,
"qk_rope_head_dim": 32,
"quantization_config": {
"bits": 4,
"checkpoint_format": "gptq",
"desc_act": false,
"format": "gptq",
"group_size": 128,
"lm_head": false,
"meta": {
"act_group_aware": true,
"auto_forward_data_parallel": true,
"damp_auto_increment": 0.01,
"damp_percent": 0.05,
"failsafe": {
"smooth": {
"group_size_threshold": 128,
"k": 2.75,
"type": "mad"
},
"strategy": "rtn",
"threshold": "0.5%"
},
"gc_mode": "interval",
"gptaq": null,
"hessian": {
"chunk_bytes": null,
"chunk_size": null,
"staging_dtype": "float32"
},
"mock_quantization": false,
"mse": 0.0,
"offload_to_disk": true,
"offload_to_disk_path": "./gptqmodel_offload/hqdpgrum-rkaakpxx/",
"pack_impl": "cpu",
"quantizer": [
"gptqmodel:5.7.0"
],
"static_groups": false,
"true_sequential": true,
"uri": "https://github.com/modelcloud/gptqmodel",
"vram_strategy": "exclusive",
"wait_for_submodule_finalizers": false
},
"pack_dtype": "int32",
"quant_method": "gptq",
"sym": true
},
"rms_norm_eps": 1e-05,
"rope_scaling": {
"long_factor": [
1.0591234137867171,
1.1241891283591912,
1.2596935748670968,
1.5380380402321725,
2.093982484148734,
3.1446935121267696,
4.937952647693647,
7.524541999994549,
10.475458000005451,
13.062047352306353,
14.85530648787323,
15.906017515851266,
16.461961959767827,
16.740306425132907,
16.87581087164081,
16.940876586213285
],
"original_max_position_embeddings": 32768,
"short_factor": [
1.0591234137867171,
1.1241891283591912,
1.2596935748670968,
1.5380380402321725,
2.093982484148734,
3.1446935121267696,
4.937952647693647,
7.524541999994549,
10.475458000005451,
13.062047352306353,
14.85530648787323,
15.906017515851266,
16.461961959767827,
16.740306425132907,
16.87581087164081,
16.940876586213285
],
"type": "longrope"
},
"rope_theta": 10000.0,
"scale_depth": 1.4,
"scale_emb": 12,
"transformers_version": "4.57.1",
"use_cache": true,
"v_head_dim": 64,
"vocab_size": 73448
}
INFO Module: Sync model.embed_tokens <- from turtle (Embedding)
INFO Module: Sync model.norm <- from turtle (MiniCPMRMSNorm)
INFO Module: Sync lm_head <- from turtle (Linear)
INFO Module: Re-tied embedding weights on shell model after full sync
INFO Module: Total synced modules: 3
INFO Pre-Quantized model size: 7770.39MB, 7.59GB
INFO Quantized model size: 2289.50MB, 2.24GB
INFO Size difference: 5480.89MB, 5.35GB - 70.54%
Quantization finished.
评论区